Example terms (or symbols) for shape labels, connection labels, merit calculation labels for developers to use for prototyping use cases.
All input is tagged
Only shape-tagged snippets of text are being tested.
These terms are either one of the 8 shapes themselves, shape labels (subshapes) or terms of deliberation.
ALL USER INPUT is nested within a shape +/- a label.
Shape tagging has been tested with the ushin semantic screen. An ushin semscreen displays 9 regions each have a distinct and consistent meaning and shape. Users tag their input by typing in an area or otherwise selecting a shape.
Semantic Screen (Semscreen) Interface
Users tag all ushin objects are tagged with one of the 8 shapes +/- a shape label. This is a requirement for submission. The semantic screen, modeled at u4u.io, is an intuitive way to tag objects. When operational the u4u right panel displays configurable related results, action options and alternate topics.
Views
- the semscreen interface displays a central main point with supporting subpoints for users to read and submit input. Subpoints may be labeled by the publishing host (in early prototypes and soon users will be able to add their own).
- Shape labels are options that users select within each of the regions to specify, for example, a type of fact
- curation displays offer each host the ability create labels, establish taxonomies, set scopes of information and publish their choices for open visibility within an (expanded) point’s merit region when point is viewed at the host
- Users can can expand the merit region to view a host’s method of arriving at the current semscreen’s merit score and adjust the scores by altering parameters
- Calculation displays offer hosts and users show how the score was obtained.
- Customization that lets user toggle among results, for example see different emotional reactions from different sets of included peers (based on host and user peer lists and the kinds of hosting)
- map, outline, list and some semscreen views display published input, for example results from a narrowed search
- Shapes, labels and point summaries and full points may be visible depending on screen size, layout and user interaction
- connection labels do not require shapes for publication, although they may be annotated, or opened as a semscreen root to usher, (create a semscreen around).
For other ways that information is filtered or ranked, such as peer and group inclusions, or search criteria, see Considering Merit.
Example Shape labels
Curators create, edit select labels
SHAPE LABELS are curator’s subcategories of each shape, as shown within the different semscreen regions.
Imbue.im, for example, will offer users lists, e.g. feelings/needs/thoughts and also topics lists that are specific to Imbue, e.g. user-selected sections of songs.
Criteria for judging merit
Curation and criteria set by user and host-publisher
Each of these sets of criteria are examples only for purposes of mocking up deliberations in development. The ushin protocol allows for user, peer group and publisher control of criteria with intuitive customization within the expanded merit region. The distributed nature of the project allows criteria to diverge and/or combine as participants connect deliberations and prune their taxonomies and merit criteria to meet their own independent and collective needs.
Merit scores may be shared and effect crowd ranking
Note that merit calculation is the subject of several webpages on this site and imbue.im. The merit regions themselves display a score which is available for community aggregation. u4u software would require a score for users to publish a semscreen with a merit tag. The other regions support this valuation by critical synthesis as part of the merit package.
Merit scores apply only to main points
Subpoints support the main point score. Users assign labels to supporting points that justify support or change of the resultant merit score. Merit scores may determine rank or even inclusion in results based on custom filters. In deliberation these points may be centralized as roots to expand the deliberation one hop out as greater scrutiny is merited.
Subpoints are not given numeric values. Subpoints inform the merit score, but are not processed by math. Regions have different kinds of considerations used to evaluate the main point in question and are described with different terms of evaluation.
Valuation Interface
When user types in the merit region, or selects the merit shape
- The semscreen displays the main point surrounded by one’s own merit-supporting draft
- Toggle between full semscreen and main point
- Click the main point to view subpoints now hidden.
- Click merit region to focus on the evaluation of the main point.
- Create one’s own text or select criteria listed within the different regions.
- These are not subcategories of shapes, as for labeling content within a region, but are judgements about about the content.
- The user’s valuation text or selected label qualifies the score. For example an action might have high value for feasibility.
Merit scores and supporting judgements may be deliberated
Other users, or oneself later, may deliberate any published merit or valuation. Merits are already a main point, supported by the user’s value labeling in the other regions. Any merit subpoint valuations may be focused as a point for deliberation. and a judgement that itself may be deliberated and value adjusted. judge the point in center by typing and selecting
Semscreen regions for judging
Actions valuatons
Actions in the process of valuation will likely base merit on related needs, if included.
- Actions, (from next to-do’s plans and strategies)
- feasibility
- possible consequences
- availability of resources
- urgency
- potency
- others …?
- feasibility
Needs valuations are specific to the situation
Unlike the generic list of human needs the valuation may be focused on the success of an action, or specific outcome.
- Needs, (requirements for health or a related outcome)
- display needs list for human needs
- action success, or other-than-human need may be deconstructed to component human needs or have focused needs defined by the situation
- urgency
- relevancy
- importance
- others …?
Topics valuations refer to the relationship with the main point
Topics are ranked on their prominence when viewing input about a main point, even whether they belong in view.
- Topics, (subjects related to the main point)
- relevance
- importance
- timeliness
- related to unmet needs
- expected or potential outcome of a given action
- others …?
Facts valuations include information source ranks and
Unlike other shapes, the default packaging mode, as presented by the Imbue prototype, requires users to label and specify their source of information.
- Facts, (evidence, events, completed actions)
- expected outcomes of actions
- personal experience
- second hand
- from list of peer-reviewed journal articles
- others …?
“People” is an ushin shape, “peers” are network participants
Note: individuals and groups mentioned in a semscreen are distinguished from peers who are sources, either authors of semscreens or publishing relays of information. Though peers may be named in semscreen people regions, as part of message content, they may or note be notified of their mention, and are likely not senders or recipients of the information containing their identity. This is typical for most communication systems – we can talk about people in our messages who don’t send, receive or even hear about the message.
People valuations are specific to the intance
One’s experience related to the main point is likely ranked higher than another descriptor or identity, however it is contextual. One’s relationships or bias may be a consideration in a merit ranking.
- People (Humans, groups, institutions …)
- For example in the Imbue.im prototype people are labeled artist, musician, orchestrator, lyricist, site editor …
- Generic labels for other examples might include:
- credentials
- experience
- relevance of experience
- other projects, interests
- third party judgments, e.g. Trustnet, to filter out bad actors and spam
- accumulated accountability for meeting needs with mercy
- system of accountability of actor
- authentication
- others …?
Thought valuations are analytical.
Thoughts valuations speak to the cogency of input. It is useful in deliberation to bring notice to confusing points and request clarification, on point, in context.
- Thoughts, (opinions, analysis, rationale)
- cogency
- logical fallacies
- methodology flaw
- clarity
- cost/benefit ratio
- modes of reasoning
- deductive – logical necessity
- inductive – suggestive by pattern
- abductive – best shot given above evidence and explanation(s)
- metrics of critical thinking, see below *
- others …?
- cogency
Feelings valuations
The software cannot generalize about whether a feeling will up- or down-rank the merit of a deliberated point. For example, one might feel horrid about whether to put down a beloved animal, yet weigh that option as most merciful given specific circumstances. So
- Feelings, (subjective emotions)
- typically a qualitative expression
- e.g. when responding to art or emotion
- under certain circumstances terms might be quantified with “positive” feelings given greater positive numeric value, for example when evaluating one’s response to art, or music.
- positive feelings could be, by default, consistent with published lists of feelings when needs are met – pleasant emotional reaction(s)
- negative feelings could be, likewise, be consistent with published list of feelings when needs are not met – unpleasant emotional reactions
- range of values could indicate author’s intensity of feeling – to be explored
- For example one might feel uncomfortable, (negative), about a fact related to a potential action. A strong negative ranking may relatively reduce prominence of the deliberated main point and possibly filter it out from view.
- typically a qualitative expression
Merits contain a single digit whole number, symbol, or term of valuation
In the imbue.im initial prototype the curators are offering both numerical and symbolic valuations. The first symbol to test is the unequal sign, to indicate an alternative to the input deliberated. The imbue.im site will experiment with averages of values based on supporting points.
- Merits (Valuations of input)
- meets specified needs
- shape-based criteria met
- For example Carol
Example connection labels
Among infinite linking phrases between pairs of nodes this list includes a few that might be a focus to support a specific merit valuation.
Add
- Furthermore
- Likewise
- Plus
Aim
- So that
- For the purpose of
- In pursuit of
- For the sake of
Cause
- Due to
- For this reason
- Resulting in
- Causing
- Leading to
Clarify
- Specify
- Name
- simplify
- explain
Contrast
- However
- Nonetheless
- Nevertheless
- On the other hand
- In contrast
- Yet
- But
- Whereas
- Conversely
- Despite this
- Although
- Even though
- Notwithstanding
- Alternatively
Compare
- Similarly
- Just as
- Compared to
- Just like
- Equally
- Like
- As with
- Equivalent to
Condition
- If
- Provided that
- Unless
- In case
- As long as
- On the condition that
- If only
- Assuming that
Exemplify
- For instance
- Such as
- Including
- Specifically
- In particular
- To illustrate
- demonstrate
- As seen in
- Like
Effecting
- influencing
- relating
- supporting
- refuting
See additional Linking Phrases
Metrics and their descriptions
Neutral ushin deliberation software does not include set tags beyond the eight shapes and basic deliberation tools. Even the default lists for generic feelings, needs and thoughts are customized in packaging steps, before publishing. Sets of subtags and metric descriptions and schema are up to publishing hosts and users.
Metric Description Schema
https://metrics-toolkit.org/about/schema
| Field | Field Description |
| Name | The name of the metric (e.g., h-index) |
| Can apply to | Indication of to what the metric is applied (e.g. an individual researcher, a paper, journal, etc). |
| Metric definition | Narrative definition of what the metric calculates |
| Metric calculation | Mathematical/quantitative definition of the metric, when available |
| Data sources | Data sources utilized to calculate metric |
| Appropriate use cases | Lists the attention/impact related questions the metric can help address |
| Limitations | Describes the limitations of the metric, as identified in the literature |
| Inappropriate use cases | Describes the attention/impact related questions the metric should not be used to address |
| Available sources | The individuals or organizations that maintain and publish the metric, with links to those sources. |
| Transparency | The ability to verify source data, and the availability of documentation about how a metric is derived |
| Website | Link to the metric’s official website, when appropriate |
| Timeframe | Time scope or coverage used in calculating the metric |
| Last updated | The date the metric description was last reviewed or revised |
For the purposes of fodder in development here are standard metrics that could be adopted in use cases:
A Guide to Peer Reviewing Journal Articles
- The article’s contribution to the discipline
- Does the article make a contribution to the discipline?
- How significant is that contribution?
- Read journal guidelines
- First reading: Overview of article and contribution
- Second reading: Detailed reading
- Do the authors adequately explain the importance of the
article in the discipline? - Is the article a good fit for the journal in question?
- Academic rigour and accuracy
- Is the methodology or argument used in the article sound?
- Does the article make a reasonable interpretation of the
data or sources? - Is there sufficient evidence to substantiate the article’s
claims? - Are the appropriate references cited, and are there any
other references that you would recommend as essential
to the article? - Are those references cited assessed fairly by the author?
- Is the information (e.g. data, formulae, quotations,
references, tables and figures) in the article accurate and
correct?
- Style and structure
- Is the structure of the article clear and well organised?
- Does the author introduce and contextualise the aims of
the article effectively? - Does the author summarise the conclusions of the article
effectively? - Is the language in the article clear and correct?
- Does the abstract accurately present the article’s aims,
argument and conclusions?
Deliberation is a manifestation of critical thinking
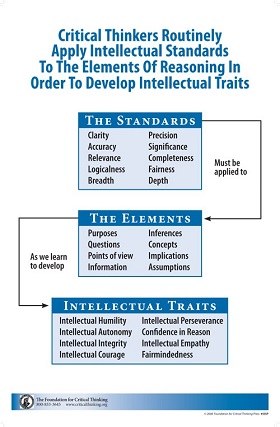
Critical thinking is that mode of thinking – about any subject, content, or problem – in which the thinker becomes aware of, and takes charge of, the structures inherent in thinking and imposing intellectual standards upon them. The ushin system suggests a particular structure to sort out 8 kinds of meanings, beyond which the structure – including the evaluation by merit scores – is open to interpretation. Regardless of how a merit score is derived, as single score values included in an open ushin-style deliberation may simplify collective evaluation with potentially meticulous scrutiny, where merited.
Terms from Critical thinking
Critical thinking is the intellectually disciplined process of actively and skillfully conceptualizing, applying, analyzing, synthesizing, and/or evaluating information gathered from, or generated by, observation, experience, reflection, reasoning, or communication, as a guide to belief and action. In its exemplary form, it is based on universal intellectual values that transcend subject matter divisions: clarity, accuracy, precision, consistency, relevance, sound evidence, good reasons, depth, breadth, and fairness.https://www.criticalthinking.org/pages/defining-critical-thinking/766
Critical thinking Standards – https://www.criticalthinking.org/data/pages/64/fece91b7d3f37c64d74d4b4e52e626b55dc9e54e1323c.jpg
{kind=link}
clarity
accuracy
relevance
logicalness
breadth
precision
significance
completeness
fairness depth
Elements of reasoning
purposes
questions
inferences
concepts
points of view
information implications
assumptions
Where to begin
Basic default options offered in the course of experimentation will derive from existing structures for understanding and sharing information. Ongoing crowd usage will refine valuation methods, taxonomies, indexing … over time.
Deliberation encorporates methods from decision making software that use intuitive scales, like the Lickert scales in “Multi-criterion voting , Collective Decision, IdeaLoom
—————————————————————————
Examples of existing systems of valuation
The following samples of methodologies is not intended to be exhaustive, or even organized or analyzed, and are included to pay homage to the complexity, and importance, of merit assessment
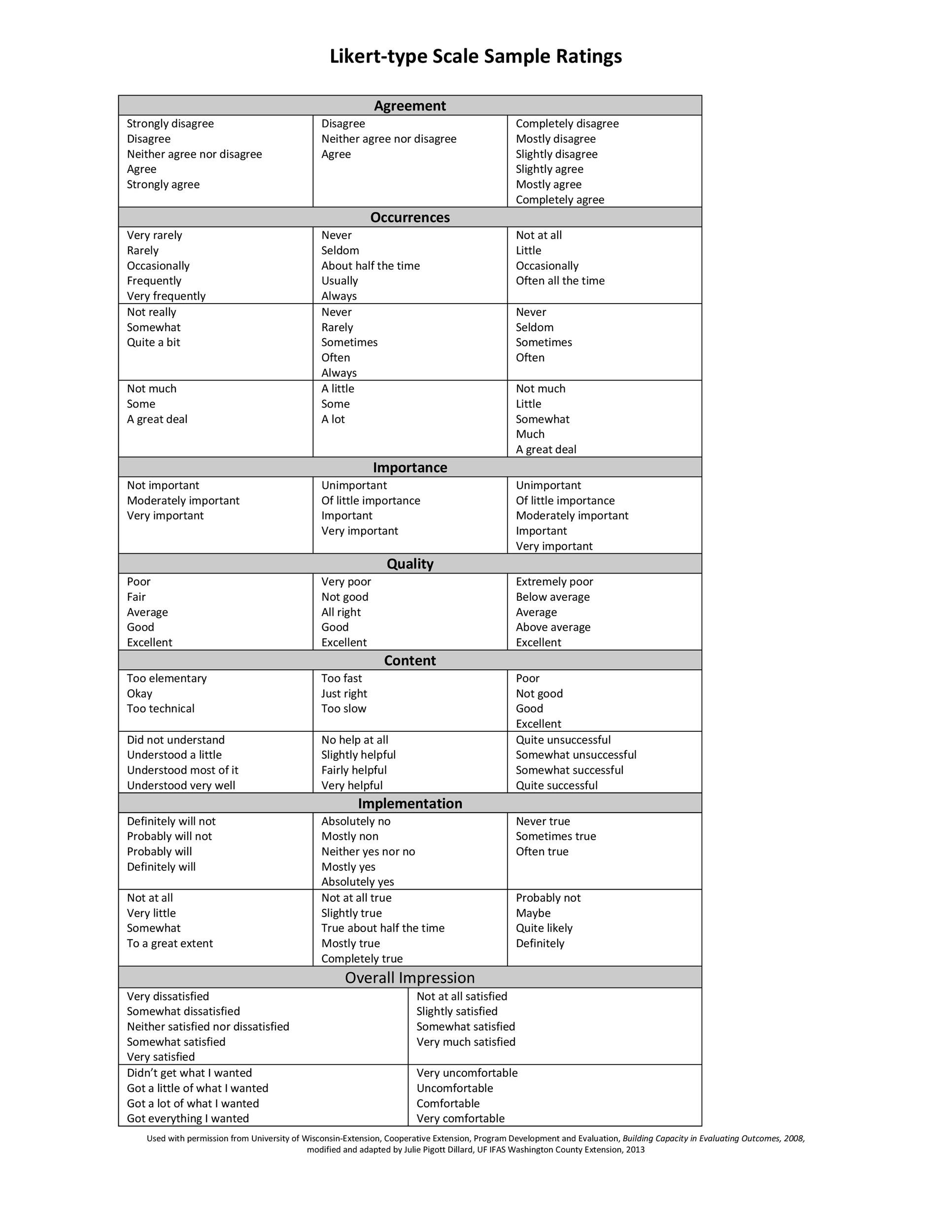
Example Ratings for Likert-type Scales
Objectifying our subjective states
Operationalization is the term used in data collection for turning abstract concepts, or subject experiences, into measureable observations. Examples include psychological studies, market surveys, behavior prediction.
This method has 3 steps:
- Identify main concept
- Choose a variable to represent the concept
- Set indicators
For example, a study showing the effect of an introduced variable, like a treatment, on a psychological state such as anxiety might use self-rating scores on social anxiety scales, number of incidents in a period of time when a person avoided crowded places, subjective intensity of symptoms in social situations. https://www.scribbr.com/dissertation/operatio