In the ushin method, the merit shape invites a synthesis of value related to a single point after considering related sub-points. While text-only input is most descriptive for merit, a numerical value is helpful to derive a group consensus on a specific point.
Inclusive deliberation allows each person or group to define their own terms of evaluations, weights and measures. Software should make it easy for users to numerically grade and quantify merit based on terms and calculations appropriate to the findings.
Initial calculations of merit will be tested in different system with different subjects including different perspectives. Here are some initial considerations for calculating merit in general.
See imbue.im for an example of how calculations are being considered around collaborative song writing.
See Fodder for Developers for metrics for shapes, labels and how this is done online.
Context-based merit assessments
Typical ranking systems cannot reflect a nuanced response to information. The ushin system of evaluating merit offers a combination of individual and crowd-sourced ranking for users to customize ranking and filtering.
Beyond yes-no decision making
While a simple yes/no vote may suffice in some use cases, for nuanced decisions in deliberation a group might choose to decide an action based on how likely it is to meet particular needs for particular people. Case-based merit assesses various shapes with contextual qualifications and weightings. Groups and hosts are free to develop their own parameters, weights and ranking methods specific to their fields of interest. Their methods, such as glossaries, taxonomies, scopes of inclusion, source criteria may be developed and shared to promote methodological consensus over time.
Evaluation of merit
Authors evaluate their input, such as conclusions, or recommended actions, based on facts, thoughts, and action feasibility with respect to meeting stated needs.
Single semscreen
Semantic screens, “semscreens”, exemplified by u4u.io, are input forms in which each region of the screen is standardized to categorize a kind of input. Each kind of input, in its own region, is valued according to its own scale, requiring different methodologies for deriving a number.

Author self-assessment
Some ushin enthusiasts consider the semscreen itself a sufficient expression of merit for its input, concluding that the method requires no summary valuation. The software built to date excludes merit for this reason and because the calculations have not yet been modeled.
The software defaults let author merit be optional, as is input for any semscreen region, or “shape”, although publishing hosts and groups might override the default in pursuit of specific input for their own purposes.
Likewise users, groups and hosts should be able to categorically include or exclude view of merit or even filter out results that include any merit given by authors for their own input.
Filters
The term “filter” in the ushin method applies to how users, groups and host curators organize information. The first line of filtering for valuable information in a mature deliberation system would be to select:
- trusted information hosts – publishers of relevant, vetted data
- peer groups respected for expertise or inclusion criteria
- relevant search terms
- appropriate recency or time-intervals
- appropriate shapes, e.g. facts or feelings …
- authorities recommended by trusted third parties
- peer review systems for p2p networks, e.g. Trustnet moderation ranking
- personally known sources of information and recommendation
- others …?
Set filters
Once information has succeeded past the filters above then users, peer groups and curators of publishing hosts will evaluate information based on their own metrics and measures using the ushin deliberative process.
Theoretically there would be several layers of input:
- Publishing nodes would propose, design, build and host sets of subjects, definitions, and parameters that promote and share their own information, ideologies and practices.
- Peer groups likewise would edit, quantify and deliberate systems that they adapt to meet their own specific interests and standards.
- End users would then be able to further refine their view, beyond selecting hosts and groups for their filtering, by weighing and sorting various factors.
Working with variable valuations
Users, groups and publishing hosts may offer their own systems of valuation of a given point. Regardless of how derived, resulting values may interoperate in different ways. They may appear nested, hierarchical, because a user may publish input through a curating group and/or curating host (if not self-published).
The neutral ushin protocol offers autonomy to groups and hosts to developing their own valuation systems and hierarchies. In other words, hosts, groups and individuals may variably resolve a single numerical result with independent factors and weights:
- Simple average
- Weighted average
- Weighted categories, including weighting of shapes
- others …?
Factors
An ongoing deliberation system should allow users to specify their own factors of evaluation. When online shopping, users may filter for results with more stars yet find on investigation that rankings span a wide variety of factors such as price, color, speed of delivery, packaging, customer support – to name a few qualifiers that are typically inspired.
Sharing Filters
Future users may be able to adopt other people’s filters to influence what shows on their own screens. This would be a rapid means of aggregating and parsing the data in deliberation. Points and semscreens appear when users’ and groups’ filters don’t exclude peers, terms, shapes, or qualifiers among those results matching search criteria.
Popularity
Deliberative depth and specificity is enhanced when popularity is eliminated, de-merited, or postponed in the development of a discourse.
Typical decision making favors the assignment of merit by popularity, +/- influences from popular marketing. Examples include contextual fashion, electoral processes, and the general availability of products in the marketplace.
Numbers of Citations
In scientific literature the number of citations are commonly considered an indicator of quality, however they reflect influence of an article without distinction of merit. Yet citation numbers:
- do not distinguish supportive from critical conclusions
- take a long time to accumulate
- involve differing patterns among various academic fields or topics
- fail when small numbers of papers are published in the field
- do not consider utility, effect, influence, relevance or other factors
- do not have consistent boundaries for inclusion
- fluctuate with time, population tested, and specific parameters such as a medication dose, timing and co-factors, e.g. intake with food, in clinical trials
Authoritative approval by variable factors
Within academia, government or business there are hierarchies and approval systems that vet information based on the institution’s criteria. While these forms of standardization simplify the development of shared databases, such systems fall prey to potential overt and covert censorship, defamation, and removal of public access to information.
In a distributed system users, groups and hosting publishers have the opportunity to create their own methods of ranking information sources as they might by topic, or sub-points, based on the use case. An open system may offer variable factors for complex deliberation of peers.
For example, peer clarity may be important for understanding, transparency for justified governance, bias for influence assessment, availability of action options for likelihood of meeting needs. An open deliberation system may also up-rank, or bring to prominence, input by publishers who are overtly transparent in their methods of deriving merit for their published points. This is in contradistinction to success indicators that rely on hidden factors. Even the most venerated institutions fall victim to hidden factoring that would be overt in an open deliberation, where controversy is invited.
Valuation
None of the shapes have their own value. The merit shape displays the values and terms given using the user and host labels.
Users and host will be able to assign relative weights to the shapes in complex averaging.
Customize filters
Users would be able to customize filters in:
- search settings to suit current search
- set preferences for general user and peer-network preferences
- set specific filters with qualifiers related to specific findings
Change results on the fly
As one may adjust search results by changing terms of search, users could also adjust search parameters to hydraulically effect results.
- users can adjust qualifiers mid-search to change results:
- e.g. downgrade a point’s merit by judging the point irrelevant or unimportant to the main point
- add or remove peer(s), hosts, filters
- adjust, indicators and methodologies
- …
Prototyping merit valuations from the heart
To model a publishing host’s control of specificity, the imbue.im page will invite feedback on specific songs and model a method to quantify subjective impressions. When people input or select input with the “feelings” region, or “shape”, the software will assign a positive value to emotions deemed positive, that is, when needs are met and a negative value to input indicating feelings when needs are not met. Users will then be able to adjust the value to indicate intensity of pleasant or unpleasant feelings.
Peer ranking
Whether and how individuals are ranked among their peers in a social network can have awkward and unfortunate consequences, as well as benefits such as helping people find what they seek. The neutral ushin interface is agnostic to the protocols for establishing the peers included to derive any particular set of results.
Note – People, (individuals and groups) mentioned in the semscreen are distinguished from peers, which are sources of information. Though a peer may be named in a semscreen in the people region, as part of the content of a message that same peer, or anyone else, is usually not part of the deliberation but in the background. This is typical for most communication systems – we can talk about people in our messages but that doesn’t mean they sent or received, or even read the message.
How peers rank each other, and the criteria for curation by publishing hosts is up the users and publishers. Users would select hosts based on their own criteria, based on their interests. They may or not provide or rank by
- aspects of user profiles
- peer or peer group rankings
- kinds of information sources
- 3rd party vetting
- funding sources
- political affiliations
- popularity
- authentication
- … others
Sending a merit
/USHIN Programs/u4u/messageicons/
While in draft view the merit appears to author within an envelope.
Levels of deliberation
Complex deliberation software will allow users to add
- breadth to any point, e.g. other examples within a shape, or members of a set, and also
- depth of analysis, by ranking types of a processes and judging methodologies.
Complex grading
Grading methods, as for scientific assessment, would build upon common methods for information and methodologies used for peer review of input* with the addition of transparent, ongoing deliberation. Open deliberation extends discussion beyond selected sources’ published findings, facts and recommendations.
Publishers might be judged by new criteria, e.g.
- inclusion of outside cross-referencing, e.g. ushin
- responsiveness to queries, how well responses are received
- tagging of original data and methods
- methodology standards and criteria for data inclusion and
- interpretation of data standards, e.g. relative and absolute values
- related projects, relationships …
- expected effect following recommendations
- others …?
Set qualifiers
Qualifications are indicators by which information is evaluated. As the indicators themselves may be ranked – not just the value of that indicator related to given point, these qualifiers themselves may be scrutinized for, e.g. objectivity, comprehensiveness, transparency and empirical methodology.
Rank qualifiers
- rank the value of each qualifier, how important, relevant, logical …
- greater number of repetitions of a given study result, or down-rank by the number of repetitions considering a similar flaw in attaining the similar result
- one might give greater value to large institutions, or down-rank them if they think that those institutions are biased in a way that effects the study outcomes
- rank by popularity, or remove it as a qualifier because it limits the scope of options considered
Calculations
As a decentralized, ongoing, system for aggregating and sharing information which is itself changing, the calculations must respond to a variety of variables, even taxonomies and methods of weights and measure proposed by individual users, their groups, and a variety of publishing node curators.
Layers of weights
- A user may review a published semscreen according to
- one’s own qualifications
- one’s peer group qualifications
- publishing hosts’ qualifications
Quantifying qualifications
Rankings could be quantified, as is typically done with Likert scales, list sorting, or number input/change… Likert type scales, see below, may be used to operationalize users’ subjective assessments of any ushin shape. For example facts may be variably ranked by importance, relevance; or feelings by levels of negative or positivity; thoughts by markers of cogency, e.g. not lacking fallacies.
Network node calculations
In a distributed network based on publishing nodes/instances/hosts/relays users begin filtering by choosing which nodes include both for publishing one’s own input and finding published input. Additionally, groups and peers may rank those nodes according to one’s own parameters, taxonomies, terms, definitions, such as a node’s handling of
- Anonymity
- Curation
- Setting hops out for peer groups
- Blocking (can be insulting, delegitimatizing, limiting…)
- Blockers
- Custom peer filters
- others …?
Users, groups and hosts could rank information sources, for example, to include or exclude certain subcategories of an ushin shape, e.g. exclude any facts not including a citation from peer-reviewed journal articles from a list of acceptable publications. Journals could be ranked such that only top-graded publications appear in results.
Peer-qualified customization
Initial versions of ushin deliberation will test very simple merit calculations regardless of valuing peers. Future hosts will curate their own peer groups and are free to experiment with and offer trust graphs or other ways to rank peers. This is outside the scope of u4u. u4u will display results from otherwise-filtered peer groups, e.g. peers published by user’s selected sources of information or chosen by oneself. Once peer information is included the interface will calculate and display results, per user/group choice of default and customized calculations.
“Let’s say that I choose to give weight to Alice’s merit valuations, and Alice gives weight to Bob’s merit valuation, and Bob gives weight to Charlie’s merit valuations. If Alice, Bob, and Charlie assign different rankings to the same semscreen, a user could calculate merit based on a weighted function of their separate inputs.“
When user includes Alice’s input, and ranks her among top sources of information to appear in general, e.g. she has won user’s trust for having contributed input which has met other people’s needs – needs that the user prioritizes.
Merit averages
To crowd-source calculate the merit of a single semscreen, or numerical values associated with main points of several semscreens, ushin software will test weighted averages, using weights given by users and then also including layers of weights from user selected groups and hosts. A complex deliberation will include levels of variable weightings that, when adjusted, effect a given point’s merit valuation.
To start modeling merit calculations, the imbue.im project will host an open deliberation, one semscreen at a time.
- users can rank published supporting points from 0-5 per shape
- users can rank relative importance of subpoints
- the software averages supporting point ranks to calculate the main point rank
- ? decide if no weight neutral region for “standing aside” which carries no weight by default, or to assign a weight if this can be customized
- ..
Ranking points with an ushin semantic screen
Each semscreen shape region when selected enlarges to show numerical and slider input
- user selects, highlights, embeds or otherwise indicates an object to evaluate
- e.g. in an ushin annotation web-app a user could highlight a snippet of text, click the ushin icon to deliberate the snippet
- a single object appears as the center focus of a draft semscreen for user input
- user’s new semscreen regions comment on input within the same region as the original’s input,
- e.g. user B might type a new thought to support or refute user A’s thought
- if B’s thought points out faulty reasoning in A’s input user B could rank that input low
- user’s new semscreen input might comment using different shapes
- e.g. user B might type a new thought to support or refute user A’s proposed action
- if B thought that A’s proposed action was highly likely to meet stated needs B could rank it highly
The ushin semscreen for merit evaluation
The draft of a single semscreen displays different prompts in the regions compared with merit-setting semscreens. See Fodder for developers.
Merit region as a workspace
- tools for valuation and overall semscreen scores appear in merit region responding to user input
Evaluation of any single object
Possible displays of ranking deliberation include
- user creates a new semscreen based on the single point
- user creates a new semscreen with focus point surrounded by published subpoints
- user creates subpoints with independent ranking of the central point
Evaluation of another semscreen
- User puts the main point in center focus
- Subpoints to be toggled in and out of view
- user’s new main point synthesizes their own commentary and subpoint revisions
- Possible comparison views, e.g. radial or table, show original and new input juxtaposed point-by-point
Merit valuations are connected to target
- when published a new merit semscreen becomes linked to the merited point
- connection lines would appear in various views
- tables, lists, juxtaposed semscreen could display connecting lines
- connection labels might show, e.g. “demerit”, “support”
- user would select connection label to view one or both semscreens
- other connections might display as sidebar lists, or in tables
- as with other displays, results hydraulically adapt to user-accepted rankings
- the link, and option to view other semscreen, would be available when either the original semscreen is viewed or the merited (based on current filters)
Layers of input effect merit
- users, groups and hosts might rank valuations by
- number and kind of shape supporting valuation
- recency, qualifications of author, citations – as with ranking if input in general
- …?
- user downranks a prior point by linking unpleasant emotional input
- upranks actions that meet specific needs
- dots to signify semscreens or points in an array of input
Connect points to deepen deliberation
Understanding deepens when different points are connected, compared and analyzed. These connections may be deliberated and given merit valuations which then impact upstream semscreen relying on values of their supporting points.
A mature deliberation system will allow users to label connections. The end labels specify a direction of flow, or a relationship (father of, member of, responding to …). A simple mind map, freeplane, demostrates the ability for users to add labels:
- at origin end of connection
- at attachment end of connection
- in the middle of connection.
Interface ideas for connection display
The merit region expands to show ways to create and view connections and their labels. Examples include
- tables of similar shaped input
- juxtaposed full and part semscreens
- result or peer lists in columns
- ven diagrams
- mind maps
- various graphs
- move high ranked point toward center in a radial display
- …
Shapes’ Weights
User may weigh shapes based on qualifications unique to their contexts.
Weighing one’s own input
While viewers may filter out self-merits, depending on the instance of ushin users may consciously set the value of each shape, and the value of the content of that shape in a given example, to evaluate the merit of our own contributions. The value of justifying one’s main and supporting points is to consider carefully what one means to say and why.
Users can publish how they value the merits of their own messages, but it is primarily an internal process for the author. Author-sourced valuations may be, by default, hidden to anyone else but the author, for personal deliberations or to scrutinize one’s work before publication. A user, group or host might exclude self-valuations from generic results, and allow access to any from the author if author published them. These may be variably ranked compared with other kinds of merit valuations.
Deliberation, not decision making
Decision making is a simple process of taking a poll around one choice at a time. Deliberation is structured process for inclusion of people and groups and diverse perspectives in thorough and unlimited considerations. These vary with context and may respect indirect influences, weigh granular factors, anticipate potential outcomes, consider how well actions might meet specific needs, derive assurances that facts are verified, analyze conclusions by how cogent and strong … Open deliberation does not limit uses of deliberative structures.
Assign values as appropriate
Users can weigh abstract ideas, relationships and aspects of relationships, organizations, effects on peoples, our societies, other animals and our environments, and weigh impact variably, as by number of future generations considered.
Where to begin
Basic default options offered in the course of experimentation will derive from existing structures for understanding and sharing information. Ongoing crowd usage will refine valuation methods, taxonomies, indexing … over time.
Deliberation encorporates methods from decision making software that use intuitive scales, like the Lickert scales in “Multi-criterion voting , Collective Decision, IdeaLoom
——————————————————————————————————————
References:
Examples of existing systems of valuation
The following samples of methodologies is not intended to be exhaustive, or even organized or analyzed, and are included to pay homage to the complexity, and importance, of merit assessment
https://metrics-toolkit.org/metrics/highlycited_awards
Citation percentiles and ‘Highly Cited’ labels
Main Point Focused Evaluation
For terms to populate use cases for ushin deliberation see Fodder for Developers. The taxonomy examples are for the purpose of deliberation rather than didactics or introspection relating to cognitive activity.
Classifying cognitive activity
The following table is used as prompts for students to demonstrate types of thinking, from listing to explaining, exemplifying, applying, analyzing, synthesizing and evaluating. In ushin the list would be displayed as topics, and comprehension, analysis, synthesis and evaluation would be subcategories of thought and application would be an action, or event (fact).
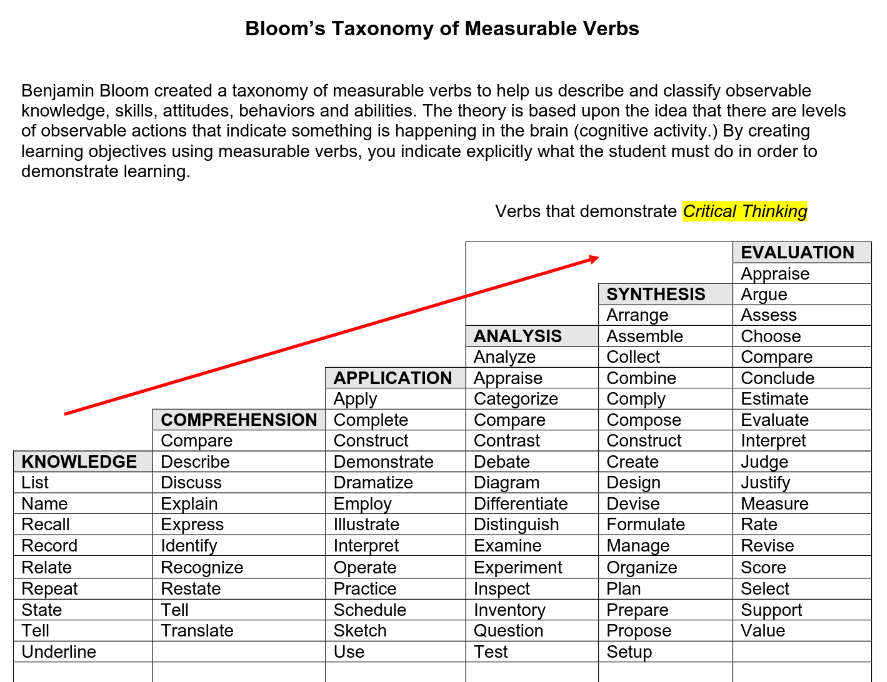
https://www.utica.edu/academic/Assessment/new/Blooms%20Taxonomy%20-%20Best.pdf
Up-front Valuation
While public information is often vetted by experts and groups prior to publication, the public is rarely included in the mechanisms and influences involved. Common crowd-sourced encyclopedia systems provide conclusive results on their front pages with presumed consensus of the editing crowd. In fact information may be hidden from most viewers, and fall prey to biased influence by hiding alternate views. Third party vetting systems are vulnerable to financial and political bias that may not appear as such to a public viewing partial or slanted information, such as limited hangouts. An open deliberation system would cross-reference to related information from other views that could be compared and contrasted using similar qualifications.